대표적인 In Memory Data Grid 인 hazelcast 에 대해서 알아보기 전에 아래의 내용을 먼저 참고 하면 도움이 될 듯 하다.
In Memory Database vs In Memory Data Grid
Redis, REmote Dictionary Server
Hazelcast?
Hazelcast 는 JAVA 기반의 In Memory Data Grid 이다.
The Hazelcast IMDG operational in-memory computing platform helps leading companies
worldwide manage their data and distribute processing using in-memory storage and parallel execution
for breakthrough application speed and scale.
출처 : https://hazelcast.com
- Hazelcast 는 분산 환경에서 데이터 공유를 위한 In Memory Data Grid 오픈 소스 솔루션
- Java 기반의 클러스터링과 확장성을 목표로 한 분산 플랫폼
- 물리적으로 떨어져 있는 두 프로그램이 하나의 자료 구조로 공유 되는 구조
Hazelcast License
- Apache License 2.0
- Enterprise Edition : Off-Heap Memory, WAN, Monitoring 기능 추가
Architecture
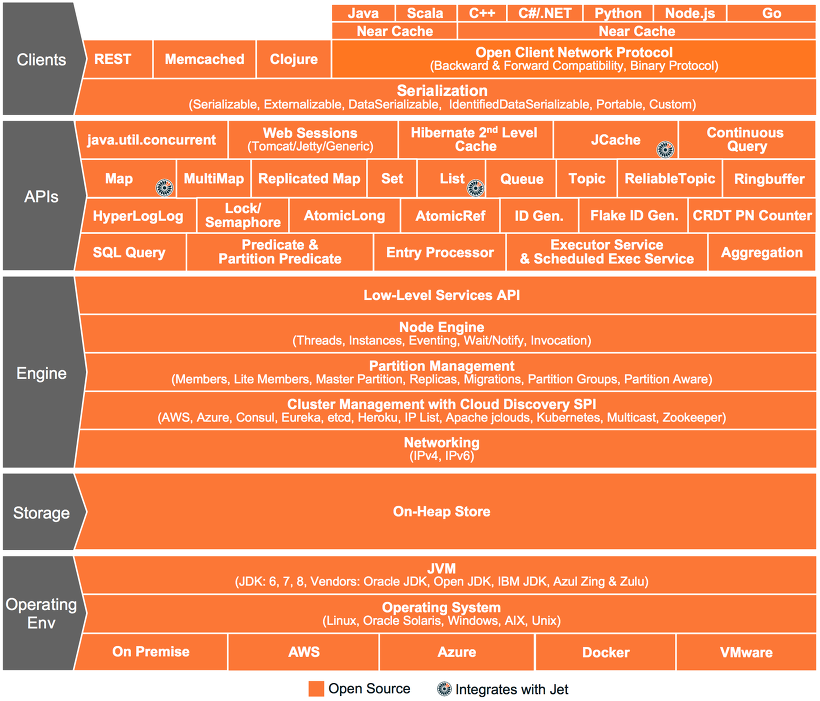
- Hazelcast 는 MMDB(Main Memory DBMS) 또는 IMDB(In Memory Database)와 발상은 비슷하지만 architecture 가 다르다.
- 저장소로 Disk 대신 여러 서버의 Main Memory 를 분산해서 저장하기 때문에 용량의 한계를 극복하고 신뢰성을 보장한다.
- Main Memory 에서 데이터를 읽어오기 때문에 속도 측면에서도 database 에서 직접 읽어오는 cache system 에 비해서 빠르다.
- 또한, Scalability 하며, 데이터 모델은 객체지향형(Serialize)이고, Non-relation 이다.
필요성
- Lightweight without any dependeny
- JVM 위에서 동작하고 시스템 종속성이 없으며, 레거시 장비를 사용해도 전체 시스템의 고도화를 이룰 수 있다.
- JVM 위에서 동작하고 시스템 종속성이 없으며, 레거시 장비를 사용해도 전체 시스템의 고도화를 이룰 수 있다.
- Key-Value store
- Java MAP API 를 통해 분산된 Key-value 스토어에 엑세스 할 수 있다.
- Java MAP API 를 통해 분산된 Key-value 스토어에 엑세스 할 수 있다.
- Distributed Map
- linear scalability
또한, 다른 IMDG 솔루션에 비해서 사용하기 매우 쉽다.
기능
기본적으로 IMDG 의 기능을 모두 가지고 있음
- Distributed Collections
- Map, Set, List 자료 구조에 분산 저장
- Map, Set, List 자료 구조에 분산 저장
- Distributed Topic & Event
- 분산 Message Queue 시스템 제공, event 순서 보장
- 분산 Message Queue 시스템 제공, event 순서 보장
- Distributed Lock
- 여러 분산 시스템에서 하나의 Lock을 사용해 동기화 가능
- 분산 환경에서 하나의 동기화된 Lock을 공유할 수 있다. 좀 더 정교한 연산 제어 가능하다.
- Transactions
- DistributedMap, DistributedQueue 등에 대한 트랜잭션을 사용할 수 있다.
- Commit/Rollback을 지원하므로 좀 더 정합한 연산을 보장한다.
- Partitioning
- 분산 노드로 데이터 분할 저장이 가능하다.(*Default)
- 분산 노드로 데이터 분할 저장이 가능하다.(*Default)
- Dynamic Clustering
- 동적인 노드 확장/축소가 가능하며, 100개 이상의 큰 노드 그룹을 지원한다.
- 동적인 노드 확장/축소가 가능하며, 100개 이상의 큰 노드 그룹을 지원한다.
- Index and Query
- 데이터 색인 및 간단한 질의문(SQL like)를 제공한다.
- 데이터 색인 및 간단한 질의문(SQL like)를 제공한다.
- Message Queue
- Distributed Topic의 경우 초당 10만 건 이상의 메시지 처리가 가능하다.
- Distributed Topic의 경우 초당 10만 건 이상의 메시지 처리가 가능하다.
- Distributed Lock
- Cache Supported
- 캐시의 특징인 Eviction, Expiration 등의 속성을 지원하며, Hibernate 2nd Level 캐시로 사용 가능하다.
- 캐시의 특징인 Eviction, Expiration 등의 속성을 지원하며, Hibernate 2nd Level 캐시로 사용 가능하다.
- Integration
- Spring Framework 및 JCA(Java EE Connector Architecture)을 통한 J2EE Container와의 손쉬운 통합을 지원한다.
- Spring Framework 및 JCA(Java EE Connector Architecture)을 통한 J2EE Container와의 손쉬운 통합을 지원한다.
- Persistency
- 전체 혹은 일부 데이터를 직렬화를 통해 영구적인 저장소로 저장할 수 있다.
- JVM의 Heap 메모리가 아닌, Off-Heap 메모리(Direct Buffer) 할당이 가능하므로, Big Memory 환경에서의 Full GC delay에 대비할 수 있다.
- 동기/비동기 쓰기를 지원한다.
- Distributed Event
- 데이터 연산에 대한 분산 이벤트가 제공되므로, 분산 환경에서의 다양한 이벤트 핸들링이 가능하다.
장단점
장점
- Full GC 제약 극복
- Off-heap 메모리(Direct Buffer) 사용하여 큰 공간을 할당할 수 있고, Full GC에 대한 부담을 줄일 수 있다.
- 큰 용량의 메모리 공간을 사용할 때 Full GC 시간을 없앨 수 있어 항상 일정한 처리 시간을 확보할 수 있다는 장점이 있다.
- 데이터는 항상 서버측 Main Memory에 저장되어 빠르다.
- 단일 또는 다중 서버에 장애가 발생할 경우, 자동으로 데이터를 복구하기 위하여 여러대의 머신에 복수개의 사본이 저장되어, 클러스터 전역에 걸쳐 데이터 손실이 발생하지 않는다.
- Masterless Nature 라는 특징을 가지고 있기 때문에, 각 노드들은 기능적으로 똑같이 구성되고 p2p 방식으로 동작한다.
단점
보통 Direct Buffer 에 대한 접근은 Heap Buffer보다 느리고, Memory Allocator를 만드는 것과 같은 매우 전문적인 기술력을 필요로 한다.