Monolithic → MSA 전환시 Network Latency
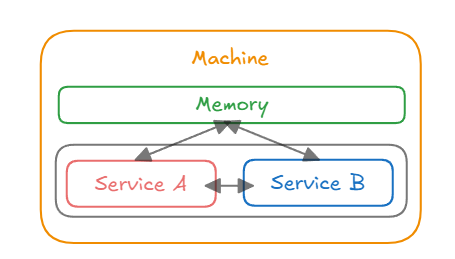
Monolithic 아키텍처에서는 하나의 Machine 에서 동일한 프로세스 내에서 실행되고, 서비스 간 통신은 메서드 호출로 이루어지므로 별도의 네트워크 통신이 필요 없다. 또한, 하나의 어플리케이션의 모든 서비스와 모듈이 동일한 메모리 공간에서 실행된다.
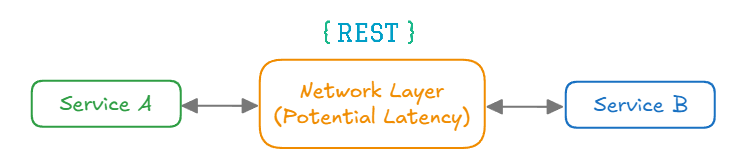
하지만, MSA 구조에서는 동일 장비가 아닐 수도 있는 여러 장비에 각각의 프로세스로 분리되다보니, 보통 REST 통신을 통해 메시지를 주고 받는 구조가 되는데(서버간 통신이 발생한다.), 이 때, 잠재적인 latency 가 존재한다. 다른 Server 나 Frontend 에서 요청을 할 때 MSA 구간별 통신이 필요하다면, 응답속도가 저하된다는 단점 이 존재하게 된다.
Q. 어떤 요인으로 인해 응답 속도 저하가 발생할까?
A. HTTP 는 기본적으로 TCP 위에서 동작하기 때문에, 데이터 송수신에 앞서 3-way handshake 과정을 거치고, 4-way handshake 과정을 통해 종료가 되는데,
MSA 구조와 같이 서버간 통신이 빈번하게 일어나서 데이터를 전송하고 응답을 받는 상황이라면, 매번 연결을 맺고 종료 하는 과정이 발생해서
비효율이 발생하게 된다.
HTTP 1.0
HTTP 1.0 은 웹의 태동과 함께 시작된 통신 표준이다.
기존의 1990년 팀 버너스리(Tim Berners-Lee) 가 최초의 웹 서버 및 클라이언트를 개발했을 때에는 상당히 단순한 구조였는데,
GET /index.html
- 헤더 값이 없으며, Content-Type 없이 HTML 만 응답만 가능했다.
- 텍스트 기반 문서 전송에만 최적화 되었고, 실제 명세도 거의 없다고 해도 무방하다.
웹의 인기가 폭발적으로 증가하며, 더 정형화된 명세의 필요성이 제기 되었고, 1996년 5월 IETF 에서 HTTP/1.0 을 공식 RFC 로 등록하게 되었다.
HTTP 1.0 의 주요 도입 요소
| 기능 | 설명 |
|---|---|
| 요청 메서드 | GET, POST, HEAD 지원 |
| 응답 코드 | 200 OK, 404 Not Found, 500 Internal Server Error 등 |
| 헤더 도입 | Content-Type, Content-Length, Date, Server, User-Agent 등 |
| 버전 명시 | 요청 라인에 HTTP/1.0 포함됨 |
| MIME 타입 지원 | 다양한 콘텐츠 전송 기능 (HTML 외 이미지 등) |
HTTP 1.1
HTTP 1.0은 요청마다 계속해서 새로운 TCP 연결을 맺은 다음에 요청을 처리하고 연결을 끊는 방식이다보니, 3-way handshake 와4-way handshake하는 과정에서
오버헤드가 발생해서 비효율적이다. 그리고 요청에 대한 응답을 받은 후에 다음 요청을 보낼 수 있어서 요청/응답이 순차적/직렬적으로 처리되어
Latency 가 발생하게 된다.
HTTP 1.1 에서는 이러한 문제를 해결하기 위해서 Persistent Connection 과 Pipelining 을 지원한다.
HTTP 1.1은 웹의 핵심 전환점이 된 프로토콜이고,HTTP 1.0 의 한계를 개선하여 더 안정적이고 효율적인 웹 통신을 가능하게 하였다.1) Persistent Connection (지속 연결)
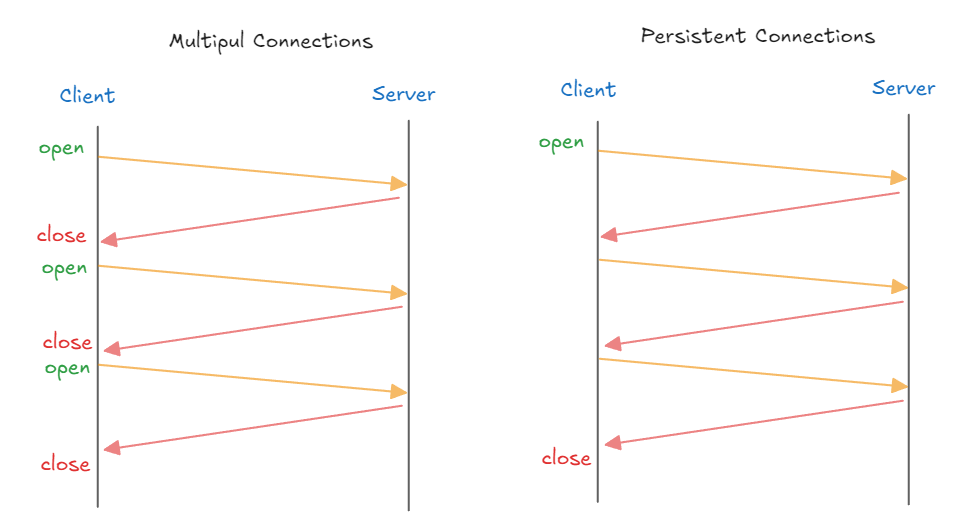
- Client ↔ Server 간 연결을 한 번 맺으면 여러 요청을 그 연결에서 처리할 수 있게 한다.
Connection: keep-alive헤더가 설정되어, Client 나 Server 가 명시적으로 연결을 끊지 않는 한 연결이 유지된다.
2) Pipelining
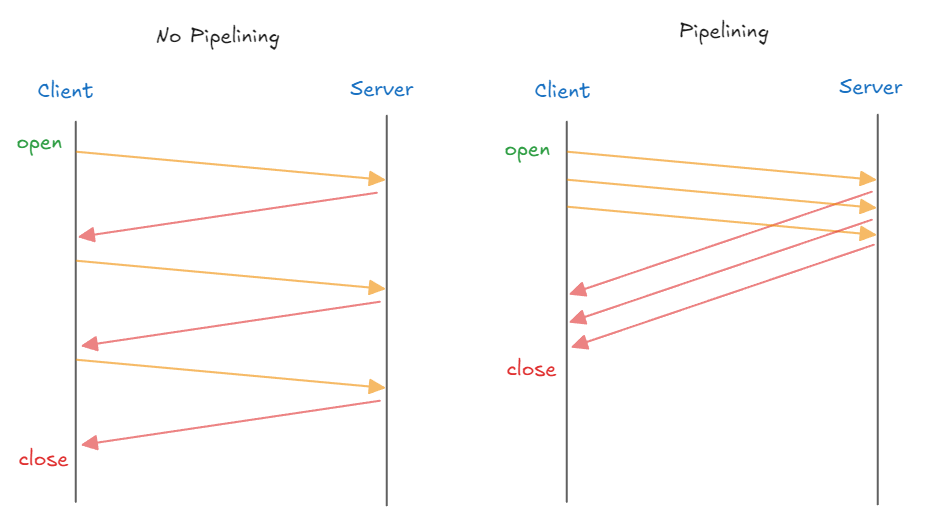
Pipelining은 Client 가 Server 에 여러 요청을 연속적 으로 보내고 순서대로 처리하는 방식이다.Pipelining이 적용되면 하나의 Connection 으로 다수의 요청과 응답을 처리할 수 있게 해서 Latency 를 줄일 수 있다.
HTTP 1.1 의 문제점
HTTP 1.1은 Persistent Connection 과 Pipelining 같은 기능을 통해서 HTTP 1.0 의 단점을 개선했지만, 여전히 여러 문제점이 남아 있다.
1) Head-of-Line Blocking (HOLB)
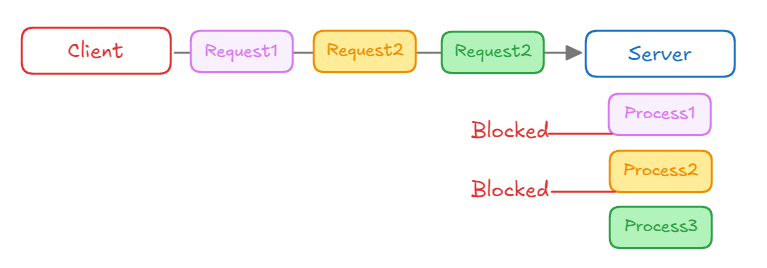
- Client 가 세 개의 요청 (Request1, Request2, Request3) 을 동시에 보내지만, Server 는 순차적으로 처리한다.
- 첫 번째 요청 (Process1) 이 처리되는 동안 다른 요청들 (Process2, Process3) 은 차단(Blocked) 되어 대기 된다.
2) Connection 관리의 비효율성
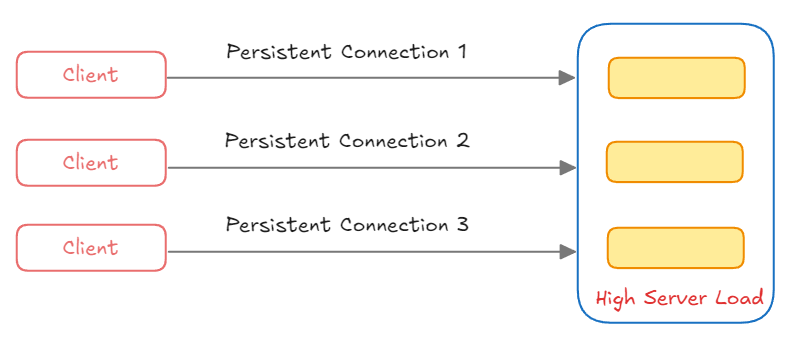
- 여러 Client 가 각각 Server 와
Persistent Connection (지속 연결)을 유지하게 되는 경우 서버는 여러 연결을 동시에 관리해야해서 서버에 부하가 갈 수 있다.
3) Header Overhead
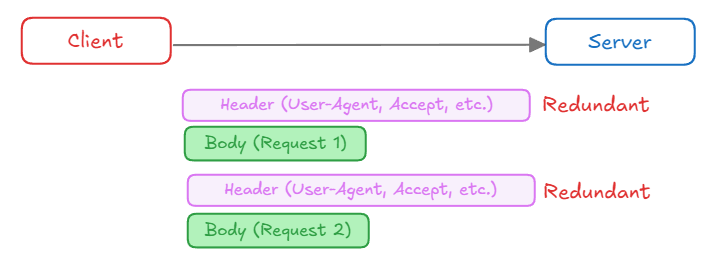
- Client 가 Server 에 여러 요청을 보낼 때, 각 요청마다 동일한 Header 를 반복해서 전송하게 된다.
- 중복된 Header 정보는 불필요한 대역폭을 차지하게 되어 효율성이 떨어지게 된다.
HTTP 2.0
HTTP 2.0은 HTTP 1.1의 문제점인, HOLB(Head-of-Line Blocking), Header Overhead, 연결 관리의 비효율성 을 해결하기 위해 설계된 차세대 프로토콜이다.
2015년 5월 RFC-7540 으로 공식 표준화 되었다.
HTTP 2.0 은 아래와 같은 주요 특징을 가지고 있다.
1) Multiplexing
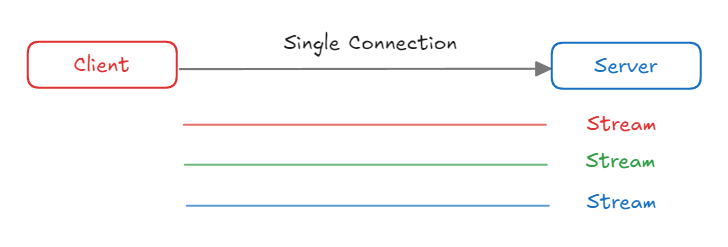
HTTP 2.0은 요청와 응답을 병렬로 처리 할 수 있는 멀티 플렉싱 이다.- 여러 TCP 설정을 할 필요 없이 한 번의 TCP 연결을 통해서 병렬로 처리할 수 있어서 네트워크 오버헤드가 감소한다.
- Client 가 여러 요청을 동시에 보내도, 각 요청이 독립적으로 처리되어서 Head-of-Line Blocking 문제를 해결한다.
- 각 스트림에 우선 순위를 할당하여 중요한 리소스를 먼저 전송할 수 있다.
2) Header 압축 (HPACK)

HPACK이라는 헤더 압축 방식을 통해 반복적으로 전송되는 헤더 정보를 효율적으로 관리하며, 데이터 전송량을 줄이고, 대역폭 사용을 최적화 한다.
3) 서버 푸시 (Server Push)

- Client 가 요청하지 않은 리소스도 Server 가 미리 전송할 수 있게 페이지 로딩 속도를 개선한다.
- 여러 요청/응답 사이클을 줄여 네트워크 사용을 최적화한다.
- 우선 순위 를 지정하여 중요한 리소스를 먼저 푸시하여 페이지 렌더링 속도를 향상 시킬 수 있다.
HTTP 1.1 과 HTTP 2.0 의 차이점
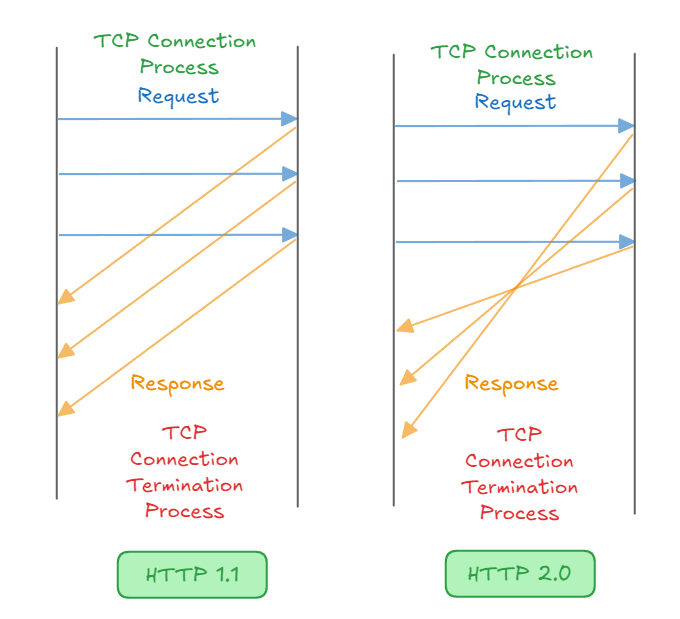
| 특징 | HTTP 1.1 | HTTP 2.x |
|---|---|---|
| Connection | Persistent Connection (지속 연결) | Persistent Connection + Multiplexing |
| Request Handling | 요청이 순차적으로 처리됨 | 요청이 동시에 처리 가능 (Multiplexing) |
| Header Compression | 없음 | HPACK 으로 헤더 압축 |
| Protocol | 텍스트 기반 | Binary 기반 |
| Prioritization | 없음 | 스트림 우선 순위 설정 가능 |
| Server Push | 없음 | 있음 |
REST API 의 단점
MSA 구조에서 서버간 통신을 HTTP/2 로만 변경해도 성능을 향상 시킬 수 있지만, REST 통신을 하게 되면 JSON으로 인한 문제가 성능에 영향을 미칠 수 있다.
1) Serialization / Deserialization

JSON은 텍스트 기반의 데이터 포맷 이므로, 네트워크 효율성이 떨어진다.- 직렬화 / 역직렬화 과정에서 CPU 사용량이 많이 필요해서 MSA 간의 빈번한 데이터 교환이 있다면, 성능 저하가 될 수 있다.
2) 타입 제약
JSON은 복잡한 데이터 구조나 날짜, 시간, 이진 데이터를 처리할 때 추가적인 파싱이나 인코딩이 필요하다.
3) 데이터 중복
- 필드를 key-value 쌍으로 표현하여 여러 개의 필드를 가진 객체에서 필드 이름이 반복되면 데이트 크기가 증가한다.
Q. gRPC 에서는 REST 의 단점을 어떻게 해결 했을까?
A. gRPC 는 protobuf(Protocol Buffers) 로 JSON 의 성능 문제 를 해결했다.
1) Serialization / Deserialization
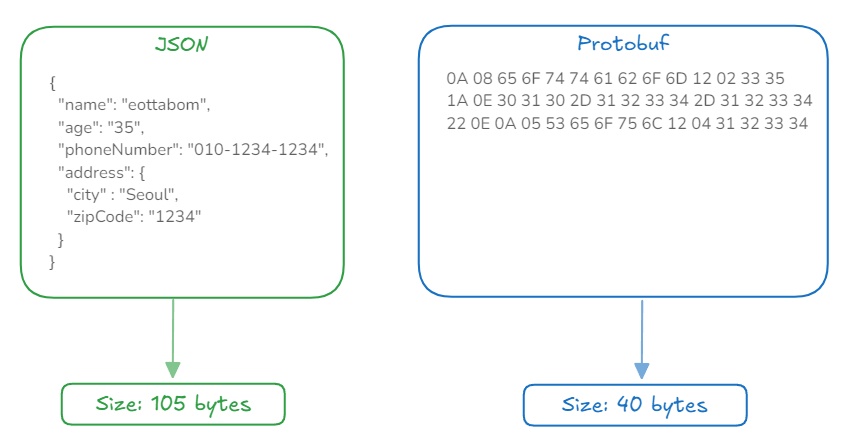
protobuf는 바이너리 형식으로 인코딩 되어 더 작은 크기를 할당한다.- 바이너리 형식은 파싱 속도가 더 빠르고, CPU 사용량도 적다.
2) 타입 제약

protobuf는 각 필드의 타입을 명확히 지정한다.JSON에서는age가 문자열로 되지만,protobuf에서는 정수형으로 정의되어 타입 불일치를 방지한다.Address와 같은 중첩된 구조를 명확하게 정의할 수 있다.
3) 데이터 중복
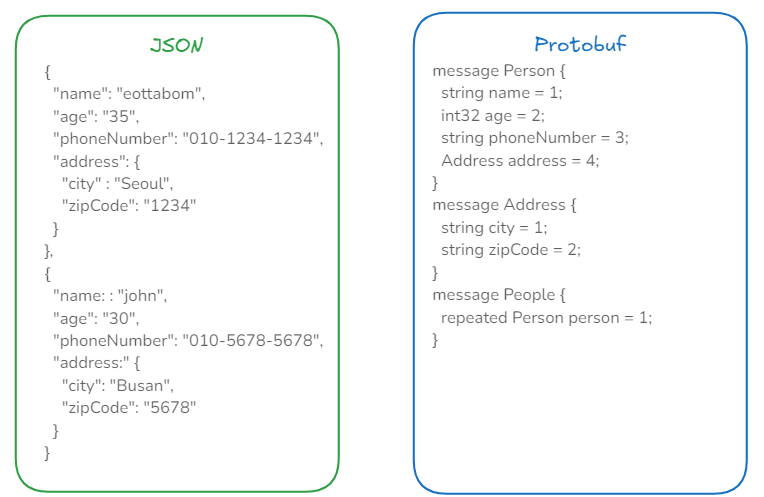
JSON에서는 각 객체마다 필드 이름이 반복되지만,protobuf는 스키마에 한 번만 정의된다.
JSON vs Protobuf 벤치마크
간단하게 http 기반 벤치마크를 돌려보면, protobuf(protobufBenchmark) 가 JSON(jsonBenchmark) 에 비해서 초당 처리할 수 있는 수가 많은 것을 알 수 있다.
| Benchmark | Mode | Cnt | Score | Error | Units |
|---|---|---|---|---|---|
| SerializationBenchmark.jsonBenchmark | thrpt | 10 | 3550.345 | ± 46.399 | ops/s |
| SerializationBenchmark.protobufBenchmark | thrpt | 10 | 4203.831 | ± 97.497 | ops/s |
Tips) gRPC 서버 와 클라이언트 동작 원리
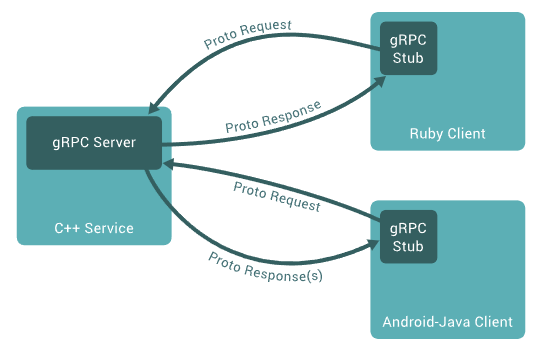
출처 : https://grpc.io/docs/what-is-grpc/introduction/
gRPC 서버
- Client 가 호출할
RPC(Remote Procedure Call)메서드를 구현 - 서버는
Protocol Buffers로 정의된 서비스 인터페이스(proto 파일) 에 따라 서버측 비즈니스 로직을 구현 - gRPC 서버는 클라이언트로부터 호출될 메서드를 구현체를 제공
gRPC 클라이언트
- 서버와 통신하기 위한
stub이라는 객체 사용 stub은 클라이언트가 마치 서버에 직접 메서드를 호출하는 것처럼 RPC 메서드를 호출하는 인터페이스 제공stub객체가 RPC 호출을 네트워크 요청으로 변환하여 gRPC 서버로 전송- 서버는 요청을 처리한 후 응답을 클라이언트로 다시 반환
1) Protocol buffers 정의
.proto파일에 gRPC 서비스를 정의한다. (GetPerson)
syntax = "proto3";
option java_package = "lego.example";
option java_outer_classname = "PersonProto";
service PersonService {
rpc GetPerson(PersonRequest) returns (PersonResponse);
}
message PersonRequest {
string name = 1;
}
message PersonResponse {
Person person = 1;
}
message Person {
string name = 1;
int32 age = 2;
string phoneNumber = 3;
Address address = 4;
}
message Address {
string city = 1;
string zipCode = 2;
}
2) gRPC 서버 구현
- 서버는
.proto파일에 정의한 서비스를 메서드를 실제로 구현하는 역할을 한다. PersonServiceImpl은.proto파일에 정의된PersonService의 메서드를 실제로 구현하는 클래스
public final class PersonServer {
private static final Logger logger = LoggerFactory.getLogger(PersonServer.class);
private PersonServer() {
}
public static void main(String[] args) throws IOException, InterruptedException {
Server server = ServerBuilder.forPort(50051).addService(new PersonServiceImpl()).build();
logger.info("gRPC server start");
server.start();
server.awaitTermination();
}
static class PersonServiceImpl extends PersonServiceGrpc.PersonServiceImplBase {
@Override
public void getPerson(PersonProto.PersonRequest request,
StreamObserver<PersonProto.PersonResponse> responseObserver) {
String name = request.getName();
PersonProto.PersonResponse response;
PersonProto.Address address = PersonProto.Address.newBuilder().setCity("Seoul").setZipCode("1234").build();
PersonProto.Person person = PersonProto.Person.newBuilder()
.setName(name)
.setAge(35)
.setPhoneNumber("010-1234-1234")
.setAddress(address)
.build();
response = PersonProto.PersonResponse.newBuilder().setPerson(person).build();
responseObserver.onNext(response);
responseObserver.onCompleted();
}
}
}
3) gRPC 클라이언트 구현
ManagedChannelBuilder로 서버와 통신할 채널 생성- stub 생성 :
PersonServiceGrpc.PersonServiceBlockingStub stub = PersonServiceGrpc.newBlockingStub(channel) stub.getPerson(request)메서드를 호출하면 클라이언트는 gRPC 서버에GetPerson메서드를 원격 호출하게 된다.
public final class PersonClient {
private static final Logger logger = LoggerFactory.getLogger(PersonClient.class);
private PersonClient() {
}
public static void main(String[] args) {
// gRPC 채널 생성
ManagedChannel channel = ManagedChannelBuilder.forAddress("localhost", 50051)
.usePlaintext()
.build();
// gRPC 서비스를 호출할 stub 생성
PersonServiceGrpc.PersonServiceBlockingStub stub = PersonServiceGrpc.newBlockingStub(channel);
PersonProto.PersonRequest request = PersonProto.PersonRequest.newBuilder()
.setName("eottabom")
.build();
// 서버에 RPC 호출을 보내고 응답을 받음
PersonProto.PersonResponse response = stub.getPerson(request);
logger.info("Server response : \n {}", response.toString());
// 채널 종료
channel.shutdown();
}
}